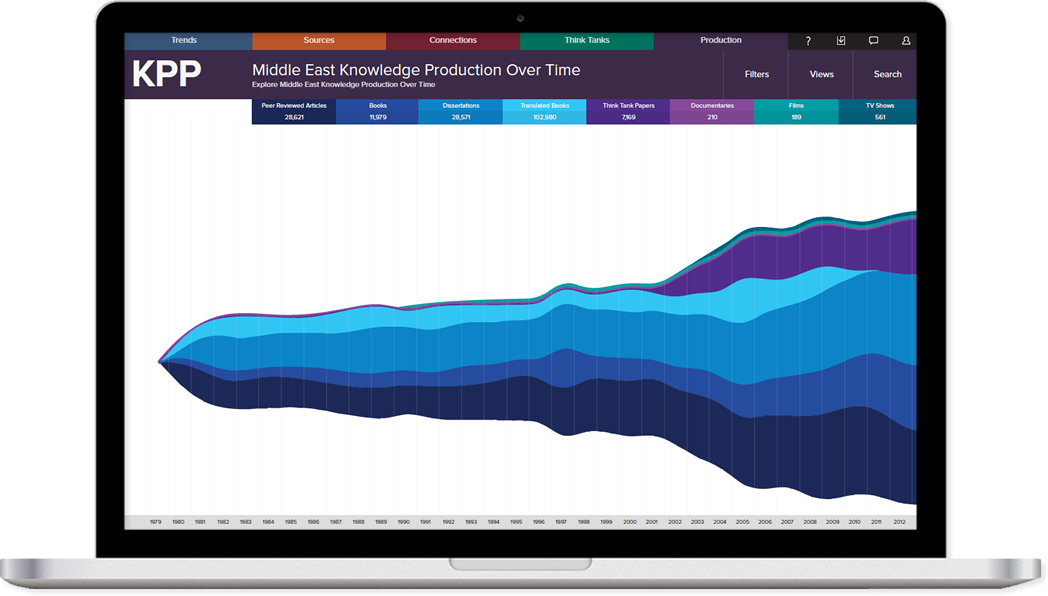
Methodology

The Objective
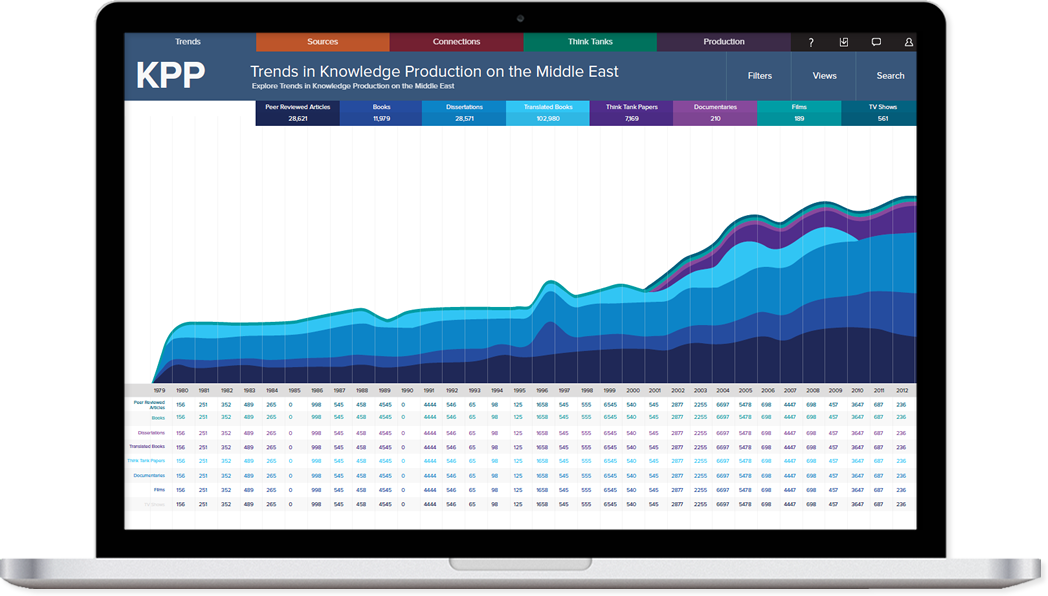
The purpose of the Peer-Reviewed Articles Database (PRAD) is to compile all scholarly, peer-reviewed articles as well as scholarly reviews of articles, books, and other works of knowledge production produced about the Arab and Muslim world from 1979 to the present. The database will provide the unique ability to see into and track the knowledge produced and consumed by academic knowledge producers.
The Sources
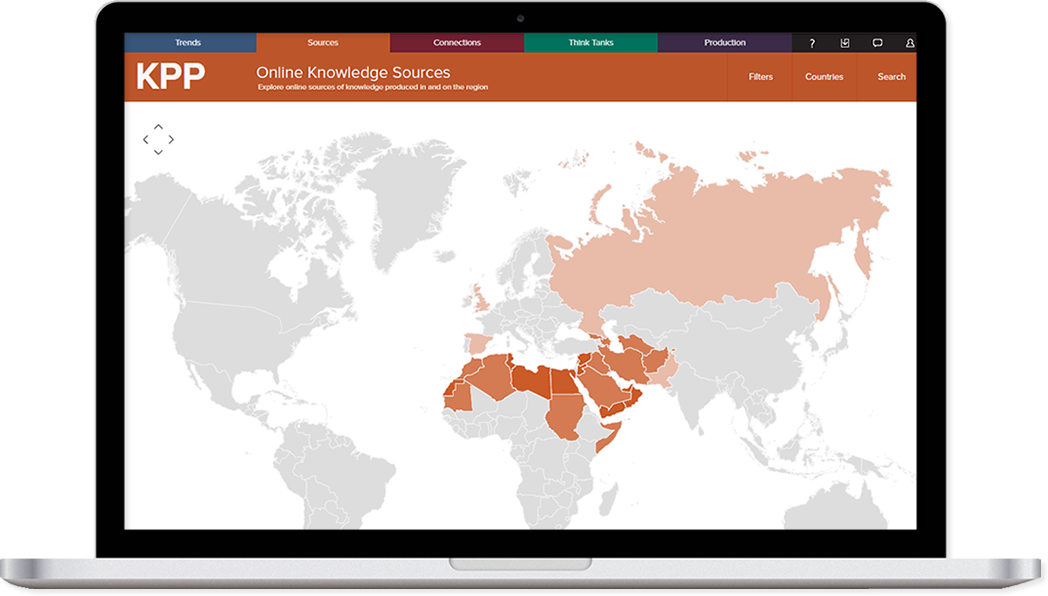
The peer-reviewed journals included in this study are chosen based on journals in JSTOR, open internet searches and third party lists of journals focusing on the Middle East. They are expanded when new relevant sources are found. As of now, the sources are all Western-based, peer-reviewed journals both currently in and out of circulation. The list from which we are currently mining contains 155 journals. All of these journals are broken up into 3 tiers:
-
Tier One: Journals focusing primarily on the Middle East or Muslim World. (For example, Arab Studies Quarterly)
-
Tier Two: Journals focusing on a major theme strongly associated with the Middle East and Muslim World or which include a large volume of articles related to the Middle East/Muslim World. (For example, Studies on Conflict and Terrorism)
-
Tier Three: Journals with no strong association to the Middle East and Muslim World, including journals around discipline. (For example, International Studies Quarterly)
The Logistics
The database currently exists in multiple Google Drive spreadsheets. After starting with one spreadsheet, it became clear that the data limitations on Google Drive required the team to create multiple spreadsheet to include all the articles for journals and years intended. Aside from the multiple databases covering the years from 1979 to the present, another spreadsheet contains the list of journals. The journals are listed along with a link to access information of published volumes, requirements for author submission, a host institution for the journal, geographic base of operations (mostly USA), the Reuters impact factor when available and the tier of the journal (for more information on the tier system, refer to the terminology page). As of January 2014, the database holds 55,011 records of peer-reviewed articles and book reviews, which marks an increase of over 16.98% since the last six month report’s.
The database undergoes two main stages of completion. The initial stage focuses on including what articles have been produced. The team records each article’s author, title, journal, year, volume and issue numbers during this stage. Each article composes one entry. All of this information is publicly available on the journal’s webpage or a subscription-based service such as JSTOR. These sources are visited and the information copied and pasted by a researcher into corresponding fields on the database.
During the second stage of the database building process, qualified researchers will analyze each article and determine the variance across new variables which include the author’s academic approach (discipline), sub-discipline, topic, subtopic, region and population studied. The formatting of the variables and cases will lead to data files conducive to analyses on a variety of software used for data analyses (such as Excel, R, SPSS, or STATA).
The number of articles that will be included in this project number in the tens of thousands. Working with an understanding of human error, the methodology includes several fail-safes where data entered in the database is reviewed and validated multiple times to assure reliability and accuracy in recording.